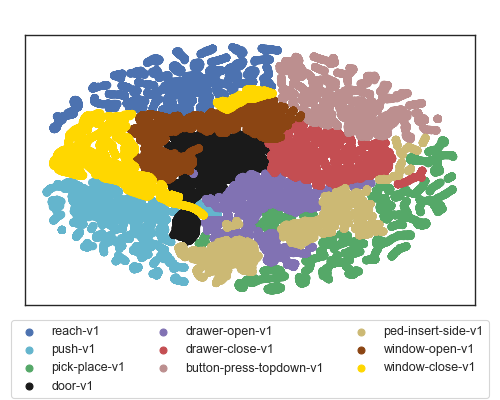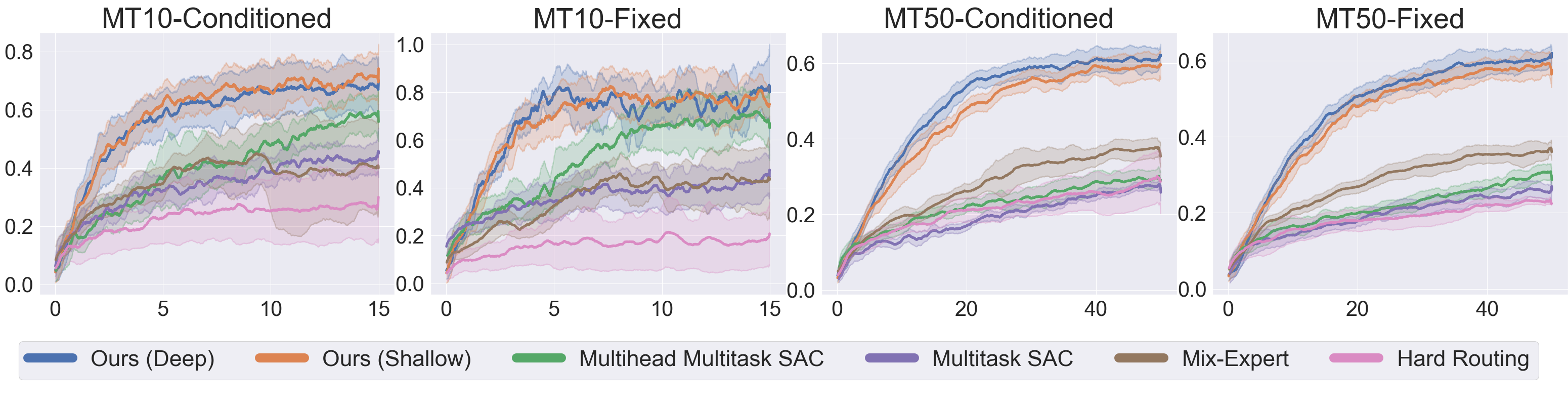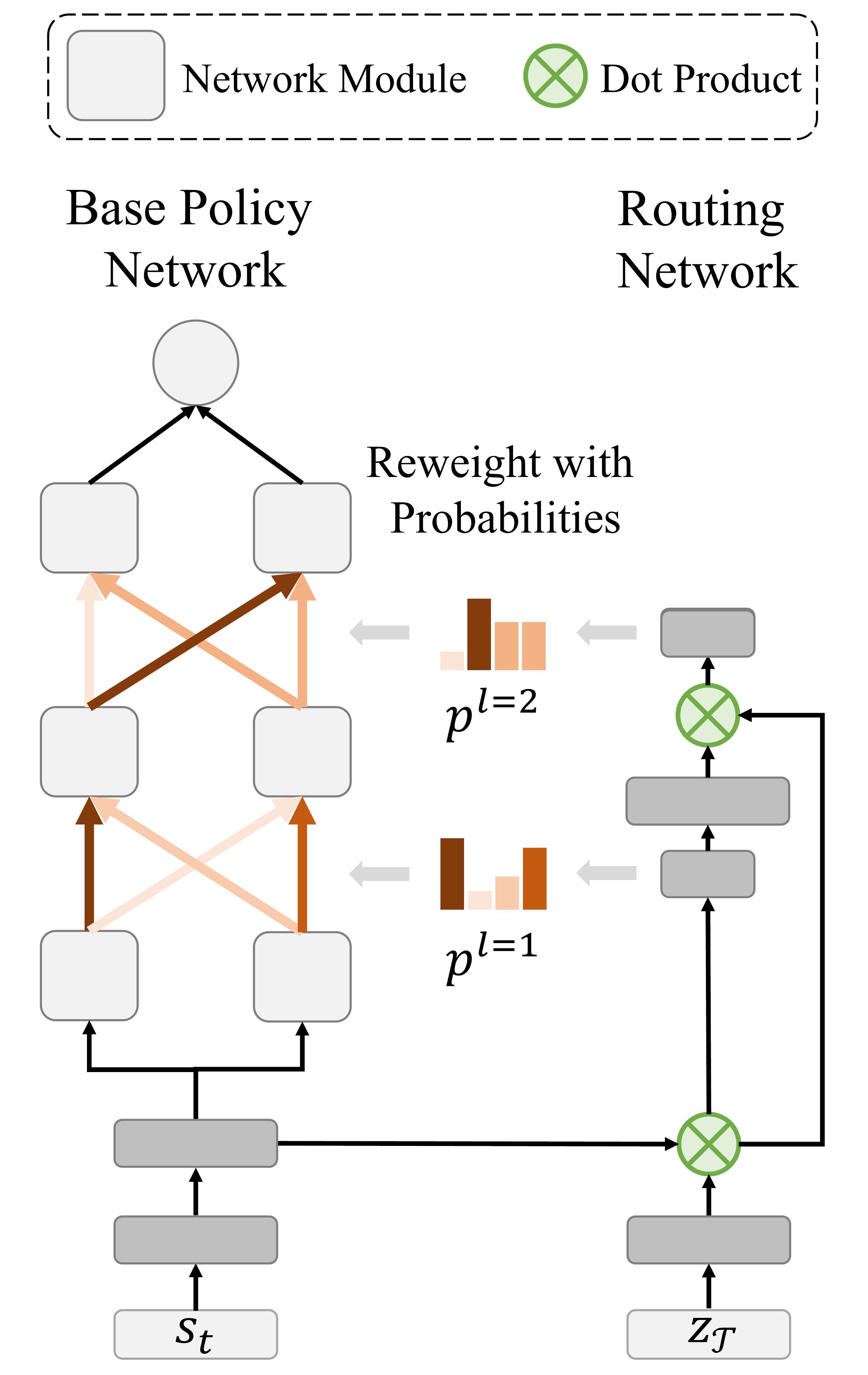
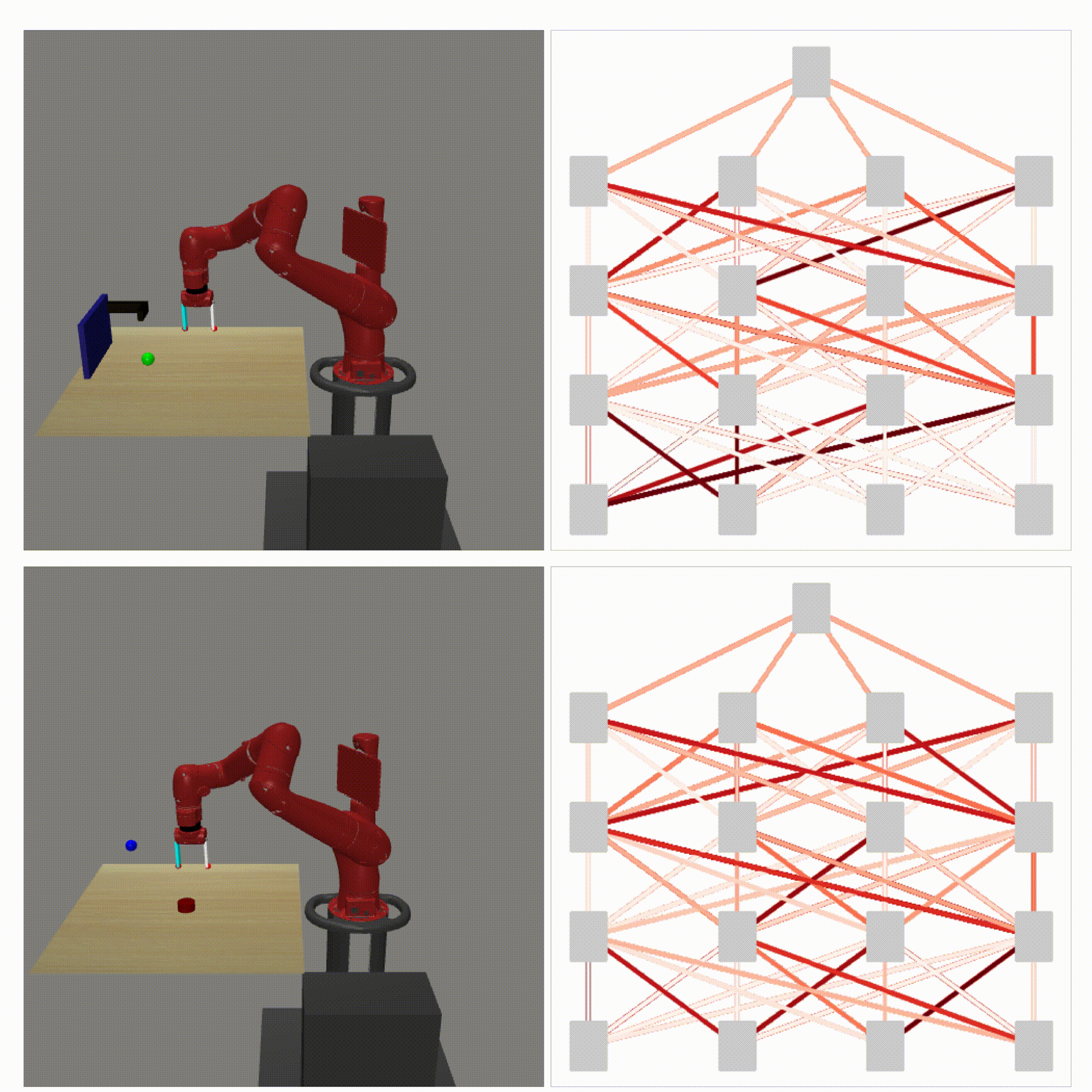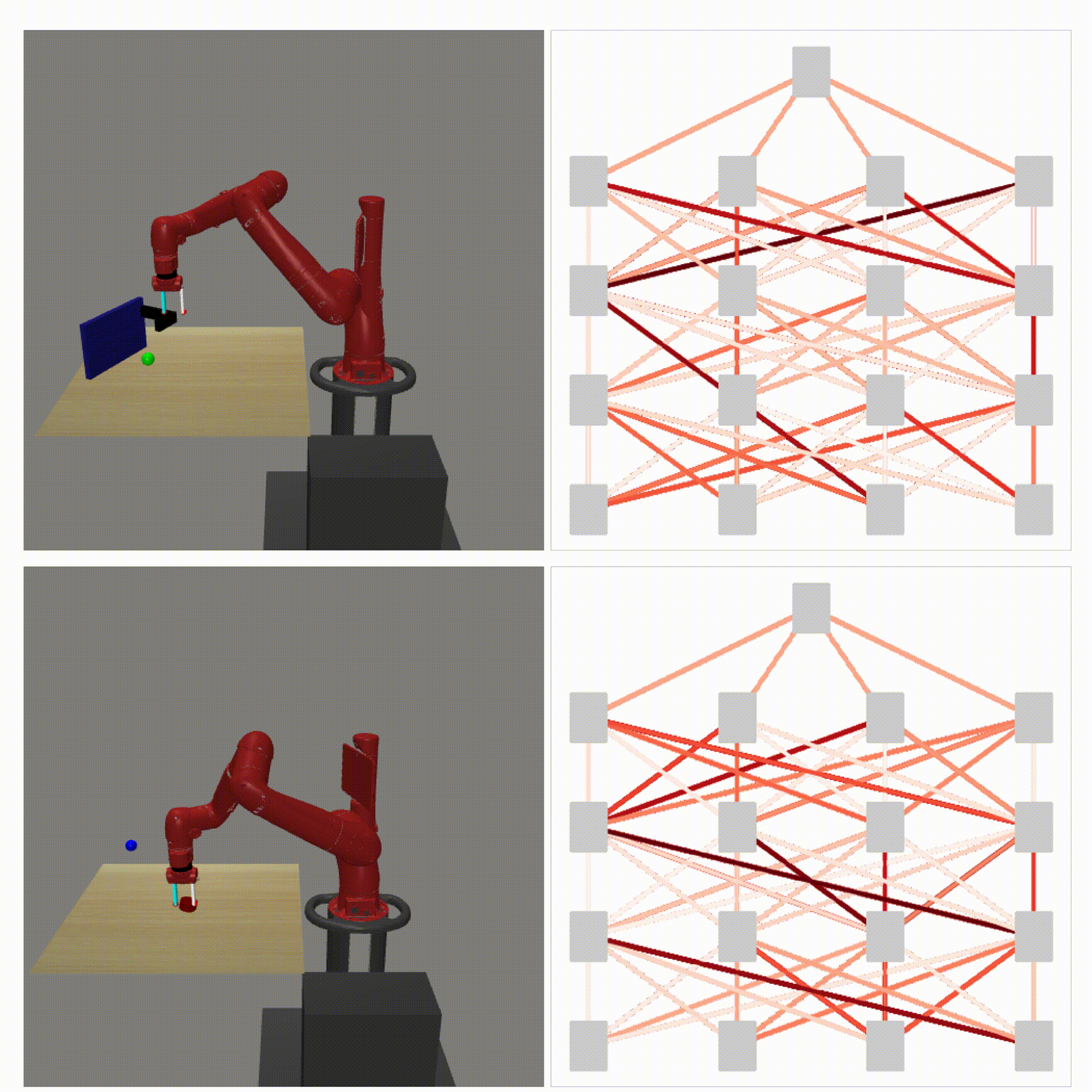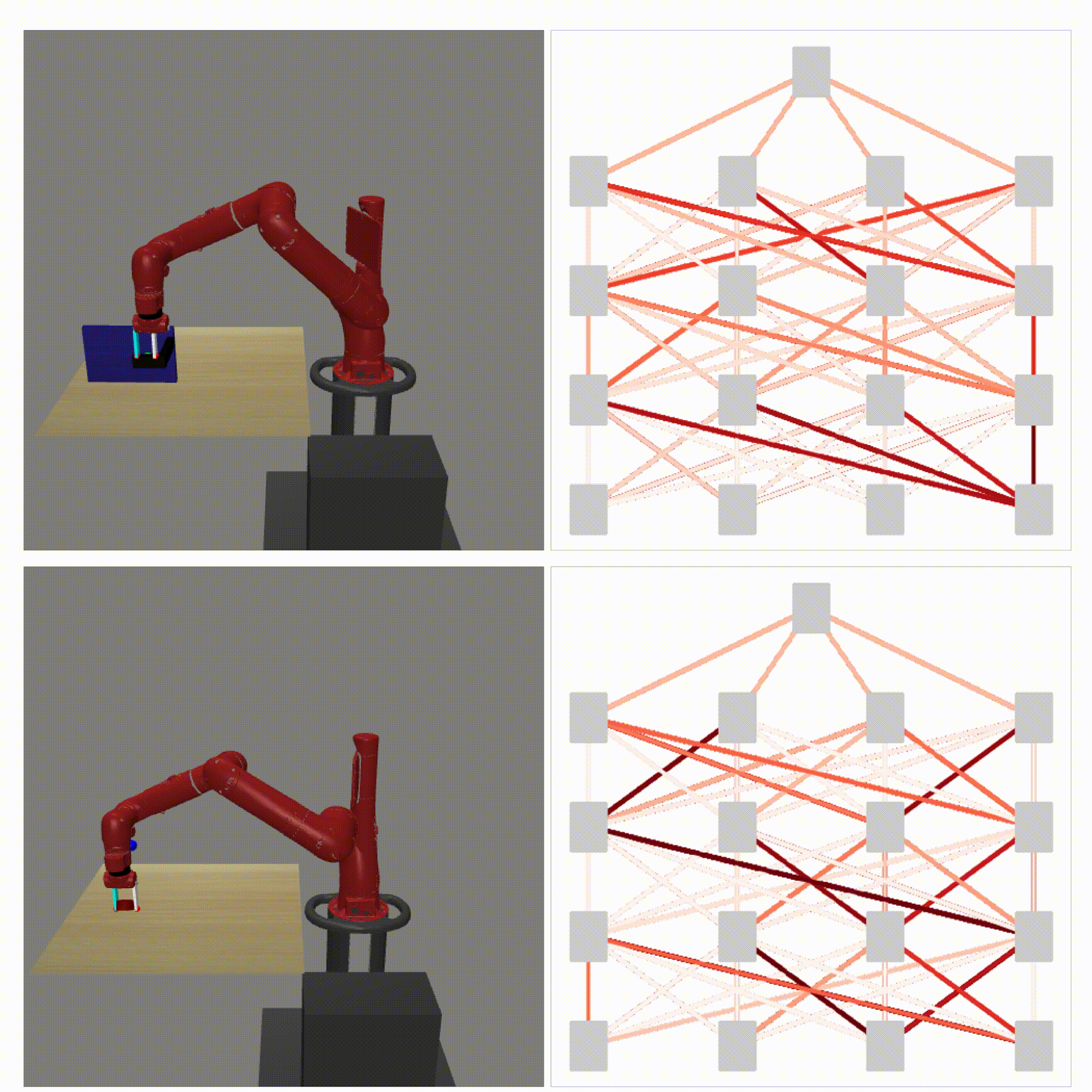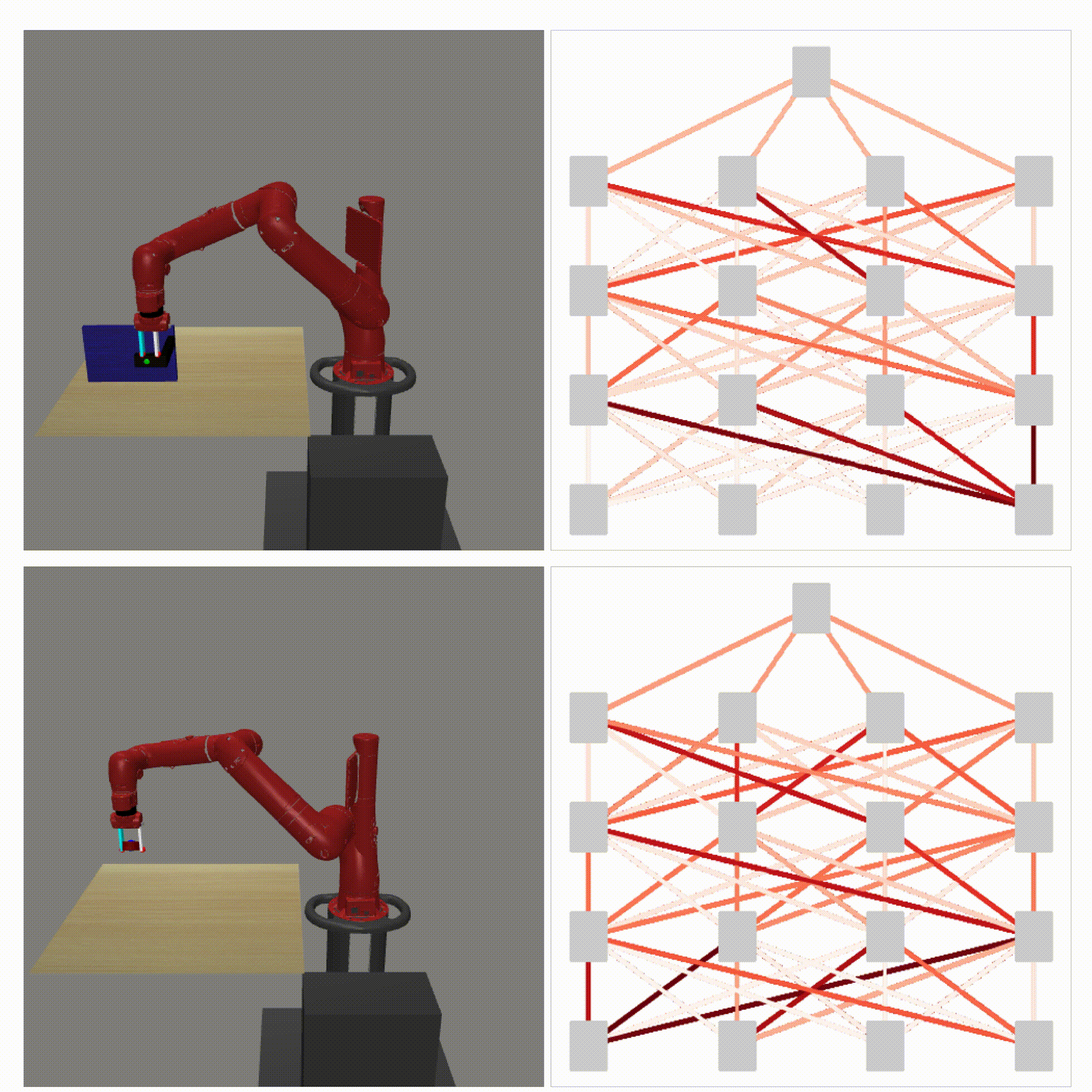
Right: Runtime visualization of our method
|
|
|
|
|
|
|
|
|
|
 |
Ruihan Yang, Huazhe Xu, Yi Wu, Xiaolong Wang Multi-Task Reinforcement Learning with Soft Modularization (hosted on arXiv) |