Fixed obstacles placed in hallway, obstacles share similar appearance with obstacles in training in simulation
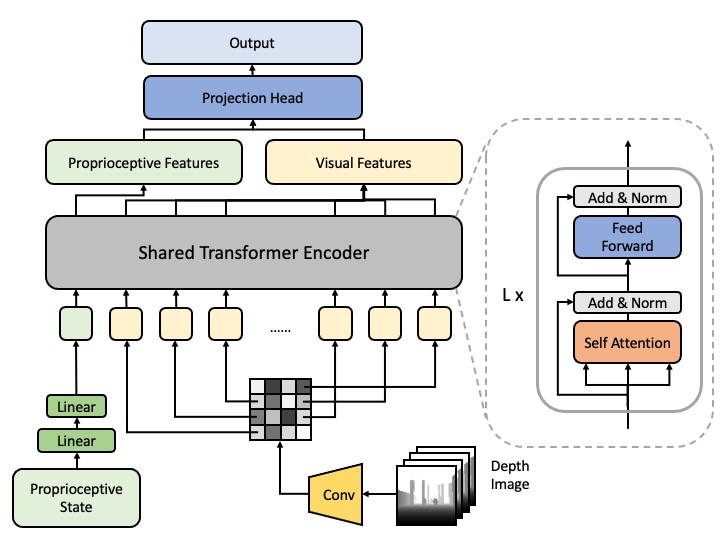
Method
We propose to incorporate both proprioceptive and visual information for locomotion tasks using a novel Transformer model, LocoTransformer. Our model consists of the following two components: (i) Separate modality encoders for proprioceptive and visual inputs that project both modalities into a latent feature space; (ii) A shared Transformer encoder that performs cross-modality attention over proprioceptive features and visual features, as well as spatial attention over visual tokens to predict actions and predict values.